Třídících metod je určitě celá spousta a všechny si je
zde uvést ani nemůžeme, rozebereme si zde pouze ty nejznámější a
nejpoužívanější. Začneme těmi jednoduššími a pomalejších a postupně se
dobereme metod náročných a rychlých.
Snad ještě hned na začátku bychom si
měli vysvětlit pár pojmů, které budeme dále používat.
Metodu nazveme stabilní, pokud pro ni platí,
že zachovává vzájemné pořadí údajů se shodnými primárními klíči.(Pokud
např. třídíme tabulku osob, primárním klíčem je pro nás příjmení osoby a
sejdou se nám v setříděné tabulce tři Nováci hned za sebou, pak se
zachovává pořadí jejích jmen tak, jak byly v původní tabulce za sebou,
ikdyž mohou být nesetříděna.)
Metodu nazveme přirozenou, pokud pro ni platí,
že doba, potřebná ke třídění již setříděné posloupnosti je menší než
doba, potřebná pro setřídění náhodně uspořádané posloupnosti.
Rychlost, nebo
také složitost algoritmu, je počet porovnání prvku,
která jsou nutná k získání setříděné posloupnosti z nesetříděné.
Označuje se O(N) a rozděluje se do skupin:
Tato třídící metoda je ze všech uvedených metod
nejjednodušší, ale také nejpomalejší. Její princip spočívá v jednoduché
záměně dvou sousedních prvků, pokud nevyhovují dané podmínce. Procedura
obsahuje dva do sebe vnořené cykly, vnější zajišťuje zmenšování počtu
prvků, které stále nejsou setříděny a vnitřní cyklus zajišťuje vlastní
výměny dvou prvků v jednom průchodu posloupností.
varpole : array[1..10]ofinteger;
procedureBubbleSort(maximum:
integer);
vark, l, pom :
integer;
begin
fork := 1 tomaximumdo
begin
forl := 1 tomaximum-1
do
begin
if (pole[l] > pole[l+1])
then
begin
pom := pole[l];
pole[l] := pole[l+1];
pole[l+1] := pom;
end;
end;
end;
end;
Existuje také vylepšená metoda Bubblesortu, ta ukončí
průchod posloupností i celé procedury, pokud je již celá posloupnost
uspořádaná, přestože oba cykly for stále neukončily
činnost, neboli pokud nenastala při posledním průchodu posloupností žádná
výměna prvků.
varpole : array[1..10]ofinteger;
procedureBubbleSort(maximum:
integer);
vark, l, pom :
integer;
vymena: boolean;
begin
vymena := false;
fork := 1 tomaximumdo
begin
forl := 1 tomaximum-1
do
begin
if (pole[l] > pole[l+1])
then
begin
vymena := true;
pom := pole[l];
pole[l] := pole[l+1];
pole[l+1] := pom;
end;
end;
ifvymena = truethenHalt;
end;
end;
Metoda Bubblesortu je přirozená a stabilní. Nejrychlejší
ze všech metod je pouze v tom případě. kdy chceme zjistit, zda je daná
posloupnost setříděná či nikoliv. Jinak je metoda nejpomalejší. Její
časová složitost (což je počet výměn,které je nutno provést k uspořádání
posloupnosti) je O(N2), protože v nejhorším případě
(kdy je posloupnost uspořádána přesně opačně než požadujeme) je nutno
provést
výměn prvků posloupnosti.
(Pozn.: Výraz
patří do O(N2), protože nejvyšší mocnina vyskytující
se ve výrazu, je N2.)
Tato metoda třídění je vylepšená metoda BubbleSort. Její
vylepšení se týká střídání směru průchodu posloupností. Zatímco metoda
BubbleSort prochází danou posloupnost pouze jedním směrem (od prvního k
poslednímu prvku), tato metoda střídá směr po každém průchodu posloupností
za opačný.
varpole : array[1..10]ofinteger;
procedureShakerSort(max:
integer);
vark, l, r, pom,
i, j: integer;
begin
l := 2;
r := max;
k := max;
repeat
forj := rdowntoldo
ifpole[j-1] > pole[j]
then
begin
pom := pole[j-1];
pole[j-1] := pole[j];
pole[j] := pom;
k := j;
end;
l := k + 1;
forj := ltordo
ifpole[j-1] > pole[j]
then
begin
pom := pole[j-1];
pole[j-1] := pole[j];
pole[j] := pom;
k := j;
end;
r := k - 1;
untill > r;
end;
Metoda je přirozená a stabilní. Časová složitost je
O(N2).
Tato metoda je založena na principu vkládání prvku na
jeho správné místo v posloupnosti. Jak si můžete porovnat předchozí výpisy
metod s výpisem této metody, používá pole o velikostí ne 10, ale 11 prvků,
počínaje již nultým prvkem. Tento se v celé posloupnosti využívá jako
pomocný prvek a samotná posloupnosti jej do sebe nezahrnuje.
varpole : array[0..10]ofinteger;
procedureInsertSort(max:
integer);
vari, j, pom:integer;
begin
fori:=2 tomax
do
begin
pom := pole[i];
pole[0]:=pom;
j:=i-1;
whilepom < pole[j]
do
begin
pole[j+1] := pole[j];
j:=j-1;
end;
pole[j+1] := pom;
end;
end;
Metoda je přirozená a stabilní. Časová složitost je
O(N2).
Metoda pracuje na principu nalezení minimálního prvku v
nesetříděné části posloupností a jeho zařazení na konec již setříděné
posloupnosti. Metoda prochází celou nesetříděnou část posloupnosti a hledá
nejmenší prvek. Až jej nalezne, vrátí se na konec již setříděné části
posloupnosti a tento nejmenší prvek zde uloží. Tyto dvě činnosti vykonává
do té doby, dokud neprojde celou posloupnost a nesetřídí ji.
Tuto metodu vytvořil jeden chytrý pán, po kterém je
metoda pojmenována a tento pán ji poprvé publikoval v roce 1959. Metoda je
velice podobná, co se její činnosti týče, metodě BubbleSort, ale je
podstatně vylepšena, a proto také podstatně rychlejší. Pan Shell tři
tvorbě této metody přišel na určité zákonitosti, jako např. na tuto, že
každý prvek se v posloupnosti přesune ve průměrném případě o jednu třetinu
celkové délky posloupnosti. Tohoto poznatku pan Shell využil a zmiňovanou
metodu BubbleSort přepracoval v tom smyslu, že měnil v každém průchodu
posloupností vzdálenost dvojic prvků, které se měly uspořádat.
Jinak řečeno: metoda pracuje tak, že neporovnává dva
sousední prvky, ale prvky od sebe vzdálené o délku d. Tato
délka se po každém průchodu posloupností zmenšuje na polovinu.
constt = 4;
vari, j, k, s,
x: integer;
m: 1..t;
h: array[1..t]ofinteger;
a: array[1..n] ofinteger;
begin
h[1] := 9;
h[2] := 5;
h[3] := 3;
h[4] := 1;
form := 1 tot
do
begin
k := h[m];
s := -k; {pozice zarážky}
fori := k+1 to
ndo
begin
x := a[i];
j := i - k;
ifs = 0 thens
:= -k;
s := s+1;
a[s] := x;
whilex < a[j]
do
begin
a[j+k] := a[j];
j := j-k;
end;
a[j+k] := x;
end;
end;
end.
Metoda není stabilní a také přirozenost metody není
jednoznačná. Vztah pro přesnou časovou složitost nebyl odvozen; časová
složitost, odvozená na základě experimentů, je O(N * (log2
N)2).
Tato metoda třídění je původní, není odvozená z jiné
metody a přišel s ní jistý pan C. A. R. Hoare v roce 1962. Obecný princip
této metody spočívá v rozdělení původní posloupnosti do N podposloupností,
pro které platí, že všechny prvky první podposloupnosti jsou menší než
všechny prvky druhé podposloupnosti, atd. Poté se každá podposloupnost
rozdělí opět na N' podpodposloupností, pro jejichž prvky
platí opět podmínka rostoucí nerovnosti, atd., až nakonec rozdělování
skončí, pokud jsou podposloupnosti prázdné.
Naše konkrétní realizace QuickSortu bude dělit vstupní
posloupnost pouze na dvě části, a to podle prostředního prvku. Abychom
docílili toho, že v levé podposloupnosti budou prvky menší než prostřední
prvek a v pravé podposloupnosti budou prvky větší než prostřední prvek,
musíme ty prvky, které jsou v levé části a patří do pravé (a naopak),
přemístit. To provádíme pomocí dvou ukazovátek, které běží každé v jedné
podposloupnosti proti sobě. Levé ukazovátko běží levou částí směrem k
prostřednímu prvku tak dlouho, dokud nenalezne prvek větší než prostřední
prvek. Pravé ukazovátko pro změnu běží pravou částí směrem k prostřednímu
prvku tak dlouho, dokud nenarazí na prvek, který je menší než prostřední
prvek. Až obě ukazovátka takové prvky naleznou, zamění je mezi sebou a
prohledávání pokračuje. Prohledávání obou částí je poté ukončeno, pokud
dojde k překřížení obou ukazovátek.
Tato metoda je pěkným příkladem ukázky rekurzivního
řešení problému, i když metoda QuickSort se dá řešit i nerekurzivně.
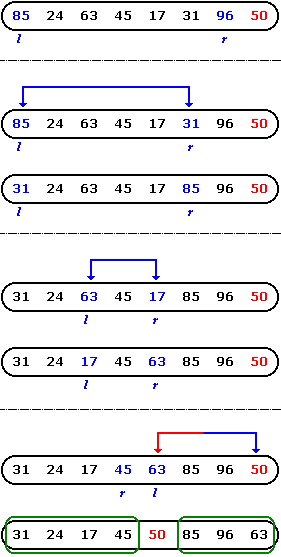
Na ukázku je vhodné uvéstjednoduchý příklad řazení
sekvence. Přesto, že se jedná o velmi krátkou sekvenci, příklad
nezobrazuje celý průběh třídění sekvence. V příkladu je pouze graficky
zobrazeno a popsáno první rozdělení sekvence (první průchod vnějšího
cyklu). V závěru jsou vyznačeny části sekvence vlevo a vpravo od pivota,
které se budou třídit (rozdělovat) totožným (rekurzivním) způsobem.
Z této ukázkové sekvence, která má více než dva prvky,
vybereme pivota (50). Pivot v
tomto případě bude poslední prvek sekvence. Ukazatel
l bude ukazovat na první prvek
sekvence (85) a
r bude ukazovat na předposlední prvek
sekvence (96).
Ukazatel l bude
procházet sekvenci zleva, dokud nenalezne prvek větší než pivot
(85). Následně prochází ukazatel
r sekvenci zprava, dokud nenalezne
prvek menší než pivot (31). Poté
se prohodí prvky na které ukazuje l
(85) a r (35).
Poté se pokračuje dál. Ukazatel
l nalezne další prvek větší než pivot
(63) a ukazatel
r následně nalezne další prvek menší
než pivot (17). Poté se opět
prohodí prvky na které ukazuje l (63)
a r (17).
Takto se postupuje, dokud ukazatel
l nebude vetší než
r. Dojde ke zkřížení ukazatelů a poté
se prvek, na který ukazuje l,
prohodí s pivotem.
Tímto způsobem dojde k již zmiňovanému rozdělení
sekvence (setříděno podle pivota). Stejným způsobem se poté setřiďuje
vlevo a
vpravo od pivota.
procedureQuickSort(l, r:
integer);
vari, j, pom, pom2:
integer;
procedureROZDEL;
begin
i := l;
j := r;
pom :=pole[(i + j)
div 2];
repeat
whilepole[i] < pomdoi := i + 1;
whilepole[j] > pomdoj := j - 1;
ifi <= jthen
begin
pom2 := pole[i];
pole[i] := pole[j];
pole[j] := pom2;
i := i + 1;
j := j - 1;
end;
untili > j;
end;
begin
ROZDEL;
ifl < jthen
QuickSort(l,j);
ifi < rthen
QuickSort(i,r);
end;
Metoda není ani přirozená, ani stabilní, ale je jedna z
nejúspěšnějších metod třídění. Časová složitost je O(N * log2
N).
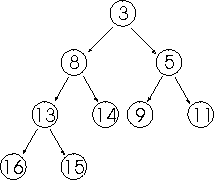
Tato třídící metoda využívá ke své činnosti právě
dynamickou datovou strukturu, a tou je halda. Popíšeme si ji
přesněji.
Halda, někdy nazývána také hromada, je binární strom,
jehož vrcholy jsou ohodnoceny celými čísly a má následující vlastnosti:
každý vrchol, který neleží na předposlední nebo
poslední úrovni stromu, má dva následníky; na předposlední úrovni stromu
následují zleva doprava vrcholy se dvěma následníky, poté vrcholy,
mající pouze levého následníka a nakonec vrcholy bez následníků;
ohodnocení libovolného vrcholu není větší než
ohodnocení libovolného jeho následníka.
Předvést si to mužeme na následujícím grafu:
Této datové stuktury se využívá k tomu, aby se do ní
uspořádaly prvky vstupní posloupnosti přesně podle pravidel, které jsme si
k haldě uvedli výše. Poté se z haldy vybírají prvky do výstupní
posloupností, počínaje minimálním (tedy nejvyšším) prvkem. Následuje výpis
v Pascalu:
Tato metoda třídí posloupnost K-místných čísel délky N a
pracuje na principu přihrádkového řazení. Zavádí se zde deset přihrádek
pomocí datové struktury fronta pro každou číslici z intervalu 0 až 9.
Vlastní třídění probíhá takto: v prvním průchodu vstupní posloupností
čísla zařazujeme do vzniklých přihrádek podle jejich poslední číslice
(jednotky), poté čísla spojíme z přihrádek do nové posloupnosti; v dalším
průchodu čísla z této nové posloupnosti zařazujeme do vzniklých přihrádek
podle jejich předposlední číslice (desítky), poté čísla spojíme do další
nové posloupnosti; takto provádíme rozdělování a spojování po jednotlivých
řádech číslic až do řádu K. Důležitá poznámka: čísla z přihrádek vybíráme
do nové posloupnosti v takovém pořadí, v jakém jsme je do přihrádek
vložili - proto využíváme datovou strukturu fronta.
Časová složitost metody je O(N) (protože
zpracováváme posloupnost délky N a to právě tolikrát, kolik je počet cifer
největšího čísla v posloupnosti). Metoda je rychlejší než metoda QuickSort,
avšak je podstatně paměťově náročná
Metoda pracuje na principu sekvenčního setřídění dvou
seřazených posloupnosti do jedné seřazené posloupnosti. Používá se pro
setřídění záznamů z dvou čí několika souborů a používá se tehdy, pokud se
záznamy k setřídění nevejdou do pracovní paměti počítače.